 1
1How to write a Financial Chatbot(First Part)-3 steps to crawl Hong Kong Stock Market (HKEX) realtime stock quotes
Navigation
In this blog, we will show you how simple it is to write a python spider to crawl realtime stock quotes from Hong Kong Stock Market (HKEX) official website. We will use the common python lib "requests" and "BeautifulSoup". And the complete code is also attached to this blog. We use Tencent(stock code: 700) as an example to show you how to to download the realtime stock price quote from HKEX's official website - Tencent Stock Price, which is valid through the time of Oct, 2023.
HKEX Website Realtime Quote
-
1. Spider URL
The most important thing of writing spider program is to find the url of the data. Let's say we want to download the realtime stock quote data of the summary section as displayed on URL (https://www.hkex.com.hk/Market-Data/Securities-Prices/Equities/Equities-Quote?sym=700&sc_lang=en). You may be curious if we can just use requests lib to GET the data from this URL? The answer is no, because this is just a page for displaying the data from the servlet, and you can't get useful data from this url.
HKEX Website Tencent Stock Quote Summary HKEX Website Realtime Quote
HKEX Website Realtime Quote
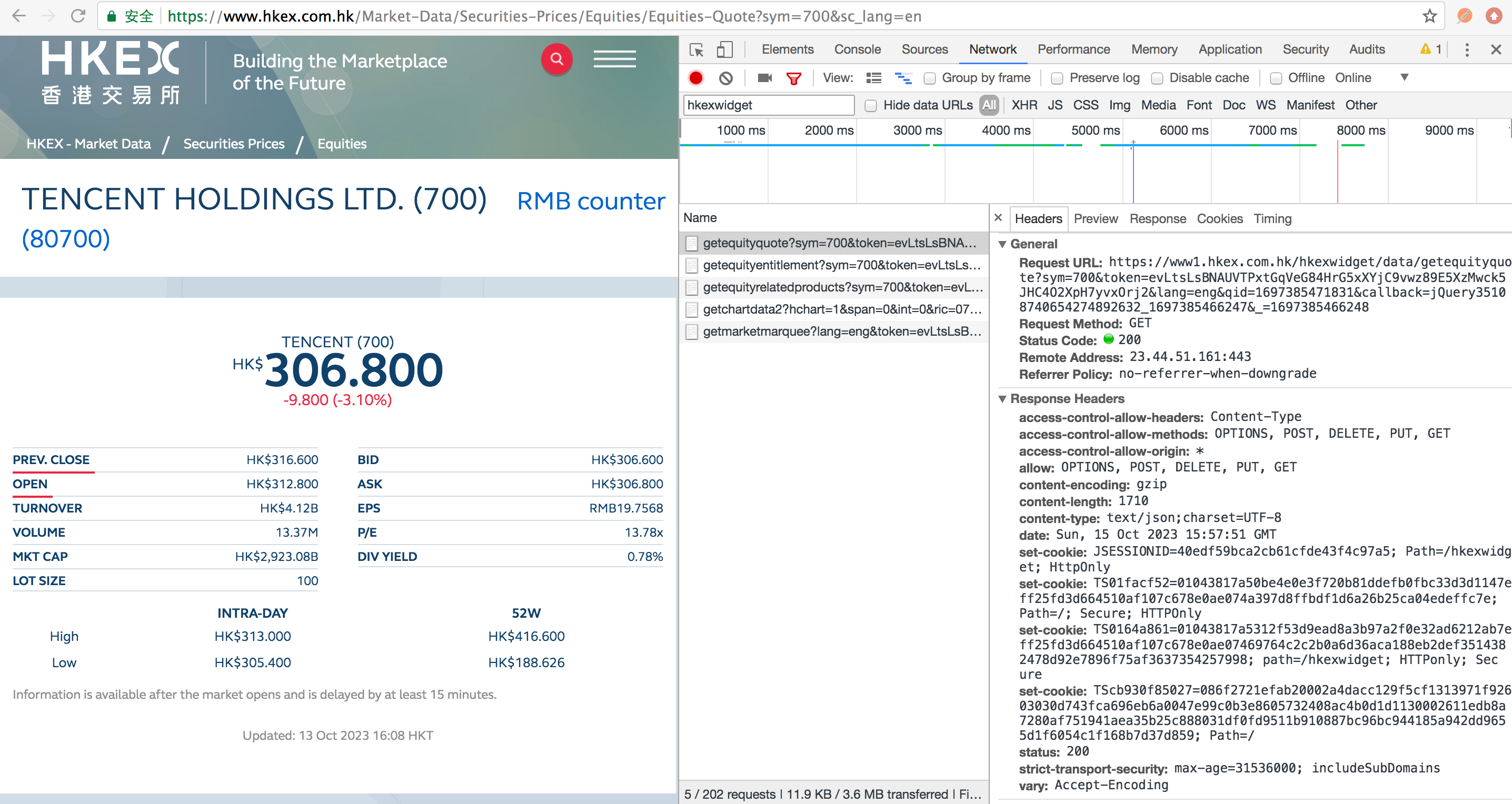
The correct way is to open your Chrome browser and find the network to see how to data service is called. And you can find the correct web servlet to host the data as in the URL (https://www1.hkex.com.hk/hkexwidget/data/getequityquote?sym=700&token=evLtsLsBNAUVTPxtGqVeG9et0X662MH%2fwrT6%2b8XWE0MkNcW%2bCSnLXhogDZ3mSR2L&lang=eng&qid=1690107390362&callback=jQuery351019444984572939505_1690107383211&_=1690107383212). The complete URL contains the part of the secret token, which will change the very first time you visit the website from brower and will expire after some time (maybe 24 hr.). The token is a string like "evLtsLsBNAUVTPxtGqVeG9et0X662MH%2fwrT6%2b8XWE0MkNcW%2bCSnLXhogDZ3mSR2L". Now the next difficult thing is to get the correct token since you don't need to manually copy the token each time you want to run the program.
Python Code
import requests import os import re import bs4 from bs4 import BeautifulSoup import sys import json import time import codecs import cachetools from cachetools import cached, TTLCache import time def get_equity_quote_data_from_hkex(token, symbol): """ URL:https://www1.hkex.com.hk/hkexwidget/data/getequityquote?sym=3690&token=evLtsLsBNAUVTPxtGqVeG9et0X662MH%2fwrT6%2b8XWE0MkNcW%2bCSnLXhogDZ3mSR2L&lang=eng&qid=1690107390362&callback=jQuery351019444984572939505_1690107383211&_=1690107383212 """ equity_data = None try: special_token_list = ["
"] if token is None: token = fetch_clean_token() timestamp = int(time.time()) url = "https://www1.hkex.com.hk/hkexwidget/data/getequityquote?sym=%s&token=%s&lang=eng&qid=%d&callback=jQuery351019444984572939505_%d&_=%d" % (symbol,token, timestamp, timestamp, timestamp) print ("DEBUG: symbol is %s, url is %s" % (symbol, url)) headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'} res = requests.get(url, headers=headers) soup1 = BeautifulSoup(res.text, 'html.parser') output_json_text = soup1.text for special_token in special_token_list: output_json_text = output_json_text.replace(special_token, "") search_result = re.search("[(]", output_json_text) if search_result is None: return equity_data start_index = search_result.span()[0] + 1 end_index = len(output_json_text) - 1 output_json = output_json_text[start_index:end_index] stock_quote_json = json.loads(output_json) response_code = stock_quote_json["data"]["responsecode"] if response_code == "000": equity_data=stock_quote_json["data"]["quote"] else: equity_data= None except Exception as e: print (e) equity_data = None return equity_data -
Secret Token
The next question is how to fetch the correct token? The answer is to first visit the normal page and the token is returned in the script section. You can use regex to parse the BASE64 token and save for future use in a short period of time, e.g. 24 hours. You can search the keywords "token" to find the correct place to parse regex.
HKEX Website Realtime Quote
Python Code
def fetch_clean_token_by_force(): final_token = "" try: headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'} page_max = 100 house = 'https://www.hkex.com.hk/Market-Data/Securities-Prices/Equities/Equities-Quote?sym=700&sc_lang=en' res = requests.get(house, headers=headers) soup = BeautifulSoup(res.text, 'html.parser') script_list = soup.select("script") special_token_mark = "LabCI.getToken" parsed_script_list = [] for script in script_list: if special_token_mark in script.text: parsed_script_list.append(script) token_area_text = parsed_script_list[0].text if len(parsed_script_list) > 0 else "" # print("DEBUG: parsed_script_list is: " + str(parsed_script_list)) if token_area_text == "": raw_text = str(soup) search_list = re.search(special_token_mark, raw_text) token_area_text = "" if search_list is not None: start_index = search_list.span()[0] token_area_text = raw_text[start_index:start_index+1000] if token_area_text == "": final_token = "" else: """ ## return "evLtsLsBNAUVTPxtGqVeG51zOWokjjvirZ7EhA46047jtmVBVWpZxDY3Mqxv4Q57"; """ search_list_start = re.search(' return ', token_area_text) start_span =search_list_start.span() ## return "evLtsLsBNAUVTPxtGqVeG51zOWokjjvirZ7EhA46047jtmVBVWpZxDY3Mqxv4Q57"; # token_len = 68 ## hk stock start_index = start_span[1] + 1 if len(start_span) > 1 else 0 # num[0] start index of string, num[1] end index of string sub_token_area_text = token_area_text[start_index:] # return end_search_list = re.search('"', sub_token_area_text) end_span =end_search_list.span() end_index = end_span[0] final_token = sub_token_area_text[:end_index] return final_token except Exception as e: print ("DEBUG: fetch_clean_token_by_force meet error...") print (e) return final_token -
Complete Program
Python Code
#coding=utf-8 #!/usr/bin/python import requests import os import re import bs4 from bs4 import BeautifulSoup import sys import json import time import codecs import cachetools from cachetools import cached, TTLCache import time def get_equity_quote_data_from_hkex(token, symbol): """ URL:https://www1.hkex.com.hk/hkexwidget/data/getequityquote?sym=3690&token=evLtsLsBNAUVTPxtGqVeG9et0X662MH%2fwrT6%2b8XWE0MkNcW%2bCSnLXhogDZ3mSR2L&lang=eng&qid=1690107390362&callback=jQuery351019444984572939505_1690107383211&_=1690107383212 """ equity_data = None try: special_token_list = ["
"] if token is None: token = fetch_clean_token() timestamp = int(time.time()) url = "https://www1.hkex.com.hk/hkexwidget/data/getequityquote?sym=%s&token=%s&lang=eng&qid=%d&callback=jQuery351019444984572939505_%d&_=%d" % (symbol,token, timestamp, timestamp, timestamp) print ("DEBUG: symbol is %s, url is %s" % (symbol, url)) headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'} res = requests.get(url, headers=headers) soup1 = BeautifulSoup(res.text, 'html.parser') output_json_text = soup1.text for special_token in special_token_list: output_json_text = output_json_text.replace(special_token, "") search_result = re.search("[(]", output_json_text) if search_result is None: return equity_data start_index = search_result.span()[0] + 1 end_index = len(output_json_text) - 1 output_json = output_json_text[start_index:end_index] stock_quote_json = json.loads(output_json) response_code = stock_quote_json["data"]["responsecode"] if response_code == "000": equity_data=stock_quote_json["data"]["quote"] else: equity_data= None except Exception as e: print (e) equity_data = None return equity_data def fetch_clean_token_by_force(): final_token = "" try: headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'} page_max = 100 house = 'https://www.hkex.com.hk/Market-Data/Securities-Prices/Equities/Equities-Quote?sym=700&sc_lang=en' res = requests.get(house, headers=headers) soup = BeautifulSoup(res.text, 'html.parser') script_list = soup.select("script") special_token_mark = "LabCI.getToken" parsed_script_list = [] for script in script_list: if special_token_mark in script.text: parsed_script_list.append(script) token_area_text = parsed_script_list[0].text if len(parsed_script_list) > 0 else "" # print("DEBUG: parsed_script_list is: " + str(parsed_script_list)) if token_area_text == "": raw_text = str(soup) search_list = re.search(special_token_mark, raw_text) token_area_text = "" if search_list is not None: start_index = search_list.span()[0] token_area_text = raw_text[start_index:start_index+1000] if token_area_text == "": final_token = "" else: """ ## return "evLtsLsBNAUVTPxtGqVeG51zOWokjjvirZ7EhA46047jtmVBVWpZxDY3Mqxv4Q57"; """ search_list_start = re.search(' return ', token_area_text) start_span =search_list_start.span() ## return "evLtsLsBNAUVTPxtGqVeG51zOWokjjvirZ7EhA46047jtmVBVWpZxDY3Mqxv4Q57"; # token_len = 68 ## hk stock start_index = start_span[1] + 1 if len(start_span) > 1 else 0 # num[0] start index of string, num[1] end index of string sub_token_area_text = token_area_text[start_index:] # return end_search_list = re.search('"', sub_token_area_text) end_span =end_search_list.span() end_index = end_span[0] final_token = sub_token_area_text[:end_index] return final_token except Exception as e: print ("DEBUG: fetch_clean_token_by_force meet error...") print (e) return final_token def main(): token = fetch_clean_token_by_force() entity_data = get_equity_quote_data_from_hkex(token, "700") print ("DEBUG: token: %s, result entity data %s" % (token, entity_data)) if __name__ == '__main__': main()The result of the realtime quote of Tencent stock price is attached below
DEBUG: token: evLtsLsBNAUVTPxtGqVeG%2fSJGKiOeWzHBmhCQdLaULdEHir%2fITnBt%2fe2wKkffmNY, result entity data {u'ew_underlying_code': None, u'h_share_flag': False, u'shares_issued_date': u'12 Oct 2023', u'ew_desc': None, u'class_A_description': None, u'class_B_description': None, u'tck': u'0.200', u'hc': u'306.800', u'floating_flag': False, u'secondary_listing': False, u'listing_date': u'16 Jun 2004', u'lo': u'', u'ew_strike': u'', u'nom_ccy': None, u'nav_ccy': None, u'ls': u'', u'hsic_sub_sector_classification': u'E-Commerce & Internet Services', u'ew_amt_os': u'', u'premium': u'', u'asset_class': None, u'f_aum_hkd': None, u'rs_stock_flag': False, u'issued_shares_class_B': None, u'issued_shares_class_A': None, u'etp_baseCur': None, u'ew_amt_os_cur': None, u'primary_market': None, u'yield': u'', u'summary': u'Tencent Holdings Ltd is an investment holding company primarily engaged in the provision of value-added (VAS) services, online advertising services, as well as FinTech and business services. The Company primarily operates through four segments. The VAS segment is mainly engaged in the provision of online games, video account live broadcast services, paid video membership services and other social network services. The Online Advertising segment is mainly engaged in media advertising, social and other advertising businesses. The FinTech and Business Services segment mainly provides commercial payment, FinTech and cloud services. The Others segment is principally engaged in the investment, production and distribution of films and television program for third parties, copyrights licensing, merchandise sales and various other activities.', u'depositary': None, u'underlying_code': None, u'ew_strike_cur': None, u'transfer_of_listing_date': u'', u'aum_date': u'', u'ew_sub_right': u'', u'primaryexch': u'HKEX', u'fiscal_year_end': u'31 Dec 2022', u'ew_amt_os_dat': u'', u'entitlement_ratio': u'', u'management_fee': u'', u'office_address': u"29/F, Three Pacific PlaceNo 1 Queen's Road EastWanchaiHong Kong", u'ew_sub_per_to': u'', u'nav_date': u'', u'issue': u'', u'bd': u'', u'listing_category': u'Primary Listing', u'strike_price': u'', u'aum_u': u'', u'isin': u'KYG875721634', u'hsic_ind_classification': u'Information Technology - Software & Services', u'updatetime': u'', u'trdstatus': u'N', u'strike_price_ccy': None, u'am_u': u'', u'domicile_country': None, u'registrar': u'Computershare Hong Kong Investor Services Ltd.', u'exotic_type': None, u'wnt_gear': u'', u'base_currency': None, u'eps': 19.7568, u'os': u'', u'multiple_counter': [{u'counter_trading_currency': u'CNY', u'counter_sym': u'80700'}], u'db_updatetime': u'16 Oct 2023 07:20', u'callput_indicator': None, u'coupon': u'', u'product_subtype': None, u'inception_date': u'', u'issuer_name': u'Tencent Holdings Ltd.', u'eps_ccy': u'RMB', u'eff_gear': u'', u'aum': u'', u'pc': u'', u'sedol': u'BMMV2K8', u'lot': u'100', u'pe': u'13.78', u'launch_date': u'', u'call_price': u'', u'product_type': u'EQTY', u'div_yield': u'0.78', u'underlying_index': None, u'nm_s': u'TENCENT', u'secondary_listing_flag': False, u'hist_closedate': u'13 Oct 2023', u'hi': u'', u'vo_u': u'', u'vo': u'', u'as_at_label': u'as at', u'incorpin': u'Cayman Islands', u'underlying_ric': u'0700.HK', u'hdr': False, u'lo52': u'188.626', u'csic_classification': None, u'mkt_cap_u': u'B', u'geographic_focus': None, u'days_to_expiry': None, u'am': u'', u'iv': u'', u'as': u'', u'replication_method': None, u'mkt_cap': u'2,923.08', u'board_lot_nominal': None, u'ric': u'0700.HK', u'exotic_warrant_indicator': None, u'inline_lower_strike_price': u'', u'hi52': u'416.600', u'nm': u'Tencent Holdings Ltd.', u'issued_shares_note': None, u'nc': u'', u'nav': u'', u'chairman': u'Ma Huateng', u'investment_focus': None, u'original_offer_price': u'', u'inline_upper_strike_price': u'', u'update_time': u'2023-10-15 23:20:03.0', u'amt_ccy': None, u'sym': u'700', u'expiry_date': u'', u'amt_os': u'9,527,658,306', u'ccy': u'HKD', u'ew_sub_per_from': u'', u'interest_payment_date': u'-', u'counter_label': u'counter', u'op': u'', u'moneyness': u''}