 2
2Introduction to Multimodal Generative Models-Model Architecture Key Features and Codes
Navigation
In this blog, we will give you a brief introduction of what are multimodal models and what can multimodal generative models accomplish. OpenAI just released their latest text-to-video multimodal generative model "SORA" in Feb, 2024 which becomes extremely popular. SORA can generate short videos of up to 1 minute's length. Before SORA, there are also many generative multi-modal models released by various companies, such as BLIP, BLIP2, FLAMINGO, FlaVA, etc. We will summarize a complete list of these time tested multi-modal generative models, introduce the model architures (text and image encoder), the training process, tasks, latex equation of loss functions, the Vision Language capabilities (such as text-to-image, text-to-video, text-to-audio, visual question answering), etc. Tag: Multimodal, AIGC, Large Language Model
What are Multimodal Generative Models
Multimodal Generative Models are generative models that takes inputs from multiple modalities, such as video, image, text and audio. It can perform various Vision Language Tasks, such as Visual Question Answering, Image-Text Retrieval, and generation tasks, such as image-to-text (Image Captioning), text-to-image(CLIP/unCLIP), text-to-video (SORA), etc.
Typical Capabilities of Multimodal Generative Models
-
Image Captioning
The image captioning task asks the AI model to generate a text description based on the image's visual content. For example, multi-modal model takes inputs from multiple modality, including the vision input as well as the textual input of prompts "A photo of...", and the model generate the full caption based on the inputs of image and text prefix "A photo of..." and complete the caption as "A photo of a monkey eating yellow bananas". Typical dataset and task include COCO, etc.
-
Image Text Retrieval
Image Text Retrieval task performs information retrieval of cross-modalities, such as image retrieval by textual embedding vector, or vice versa text retrieval by input image embedding vector. The feature is extremely useful in modern search engine. Typical dataset include COCO and Flickr30K, etc.
-
Text-to-Image
User inputs textual prompts and the model encodes the inputs using LLM and outputs the image as a sequence of patches. Many AIGC scenarios are applications of text-to-image tasks, such as GPT-4V and Genimi.
-
Text-to-Video
User inputs textual prompts and the model encodes the inputs using LLM and outputs a complete video, such as SORA, Pika and Runway, etc.
-
Visual Question Answering
Visual Question Answering (VQA) is a task in computer vision. The tasks involves answering questions about an image. The goal of VQA is to teach machines to understand the content of an image and answer questions about it in natural language.
List of Multimodal Models, Architectures and Key features
| Model | Year | Developer | Modality | Architecture | Key Features |
| SORA | 2024 | OpenAI | Video,Text | Image Encoder: Diffusion DiT | Generative Modeling,Text-to-Video |
| Gemini V1.5 | 2024 | Video,Text,Audio | Image Encoder: ViT,Text Encoder:Transformer | Generative Modeling,Long Context Window | |
| BLIP2 | 2023 | Salesforce Research | Image,Text | Q-Former: Bridging Modality Gap,Image Encoder: ViT-L/ViT-G,Text LLM Encoder: OPT/FlanT5 | Generative Modeling,Image-to-Text,Visual Question Answering,Image-to-Text Retrieval |
| GPT-4V | 2023 | OpenAI | Image,Text | Text Encoder: GPT | Generative Modeling,Multimodal LLM,Visual Question Answering |
| LLaVA | 2023 | Microsoft | Image,Text | Text LLM Encoder: Vicuna,Image Encoder:CLIP visual ViT-L | Generative Modeling,Visual Instruction Generation |
| KOSMOS-2 | 2023 | Microsoft | Image,Text | Vision encoder , LLM Encoder: 24-layer MAGNETO Transformer | Multimodal Grounding,Language Understanding and Generation |
| PaLM-E | 2023 | Image,Text | Image Encoder: ViT encoding | Multimodal Language Model | |
| BLIP | 2022 | Salesforce Research | Image,Text | Image Encoder: ViT-B,ViT-L; Text Encoder: BERT-Base | Generative Modeling,Bootstrapping,VQA,Caption Generation |
| FLAMINGO | 2022 | DeepMind | Image,Text | Gated Cross Attention,Multiway Transformer,ViT-giant | VQA,Interleaved Visual and Textual Data |
| upCLIP | 2022 | OpenAI | Image,Text | CLIP ViT-L,Diffusion Prior/Autoregressive prior | Generative Modeling,Text-to-Image,Image Generation,Diffusion Models |
| BEiT-3 | 2022 | Microsoft | Image,Text | Text Encoder: OPT/FlanT5,Image Encoder:ViT-L/ViT-g | Object Detection,Visual Question Answering,Image Captaining |
| CLIP | 2021 | OpenAI | Image,Text | Text Encoder: Transformer; Image Encoder: ResNet/ViT | Multimodal Alignment,Zero-Shot Learning |
| ALIGN | 2021 | Image,Text | Image Encoder: EfficientNet,Text-Encoder: BERT | Multimodal Alignment,Image-Text Retrieval |
Detailed Introduction
-
SORA
Explanation
As introduced on the OpenAI website, SORA is "text-conditional diffusion models" trained jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that operates on spacetime patches of video and image latent codes. Our largest model, Sora, is capable of generating a minute of high fidelity video.
How does SORA work


SORA is a text-conditional diffusion models trained by internet scale video dataset. The model performs a text-to-video generation task. First of all, SORA align the inputs of video to split the visual data of video into patches as visual representations, which are then compressed to low-dimensinal latent spaces. The original patches then goes through a Video Compression Network to further reduce the dimensions of video patches. Unlink a static image, the video has space time consistency, and SORA treats the spacetime patches of video as patches in Transformer. During the training, SORA applies the diffusion techniques, which means given input of noisy patches, the model will predict the original clean patches. For the training process, SORA uses the diffusion transformer architucture, which proves to be very effective in many Computer Vision tasks.
Related Documents
Related Videos
-
BLIP2
Explanation
How does BLIP2 work
BLIP-2 is a generic and efficient pretraining strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pretrained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model.
BLIP-2 is trained in several tasks, including:
- Image-Text Contrastive Learning (ITC)
- Image-grounded Text Generation (ITG)
- Image-Text Matching (ITM)
Pre-trained image encoder and LLM:
- Image Encoder: ViT-L/14 from CLIP (Radford et al., 2021), ViT-g/14 from EVA-CLIP (Fang et al., 2022).
- LLM Encoder:OPT model, FlanT5 model family
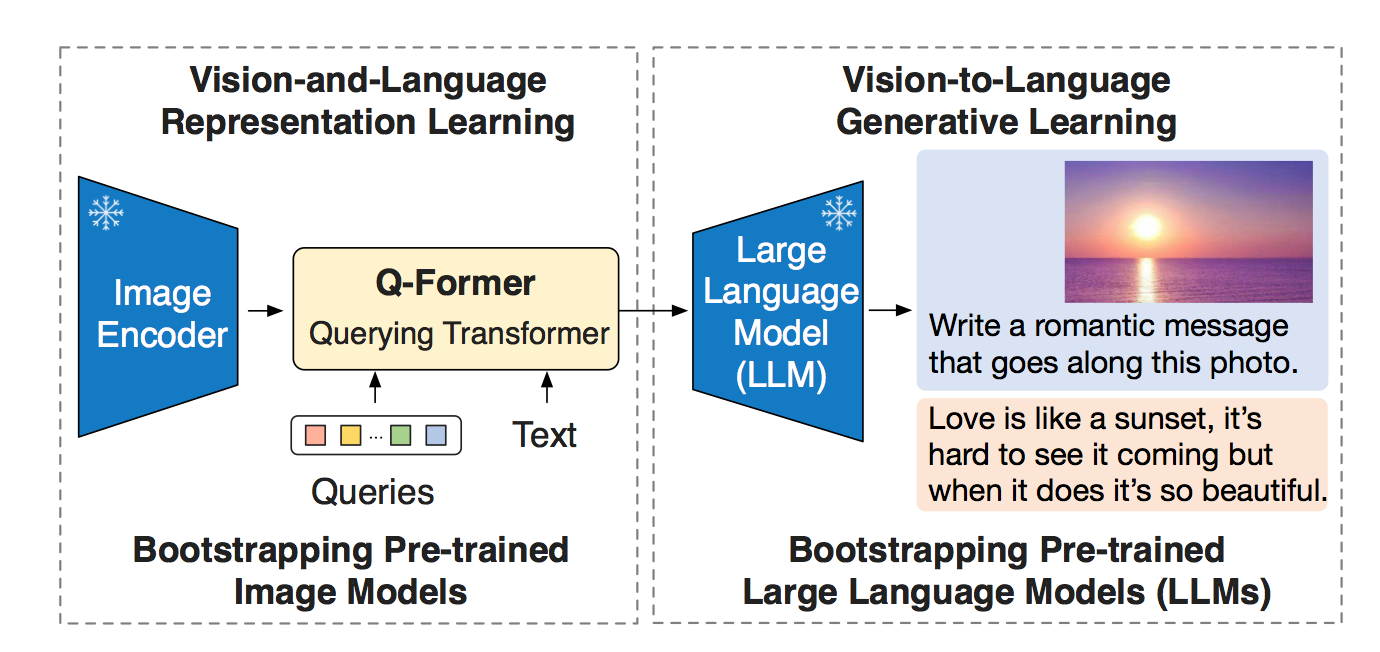
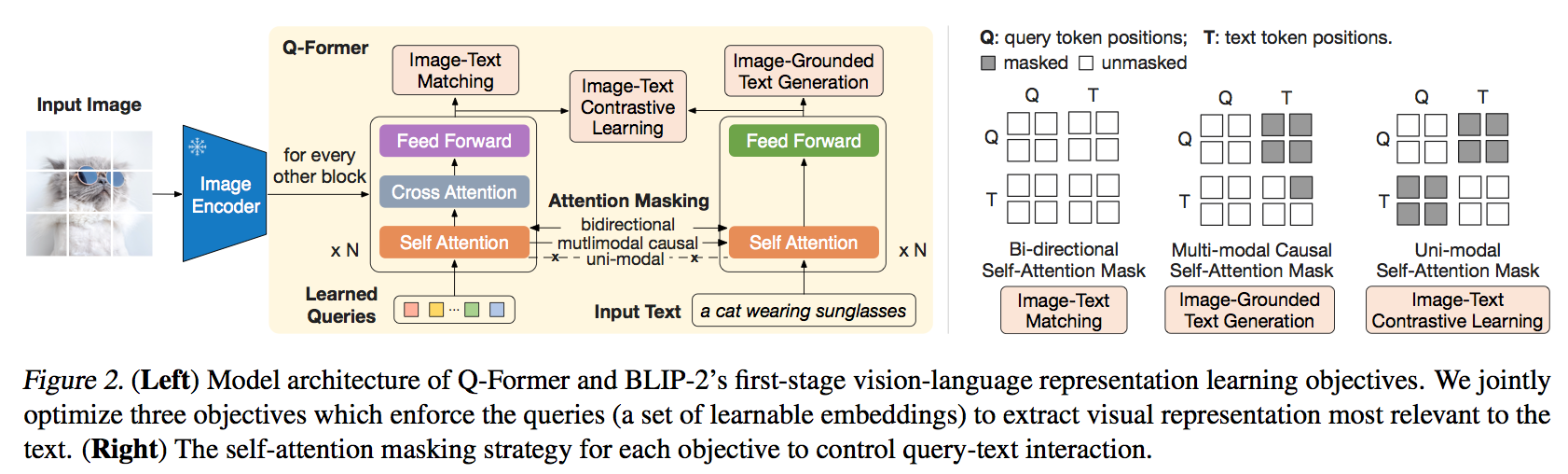
Related Documents
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- https://github.com/salesforce/LAVIS/tree/main/projects/blip2
Related Videos
-
GPT-4V
Explanation
How does GPT-4V work
GPT-4, a large-scale, multimodal model which can accept image and text inputs and produce text outputs. While less capable than humans in many real-world scenarios, GPT-4 exhibits human-level performance on various professional and academic benchmarks, including passing a simulated bar exam with a score around the top 10% of test takers. GPT-4 is a Transformer- based model pre-trained to predict the next token in a document. The post-training alignment process results in improved performance on measures of factuality and adherence to desired behavior. A core component of this project was developing infrastructure and optimization methods that behave predictably across a wide range of scales. This allowed us to accurately predict some aspects of GPT-4’s performance based on models trained with no more than 1/1,000th the compute of GPT-4.

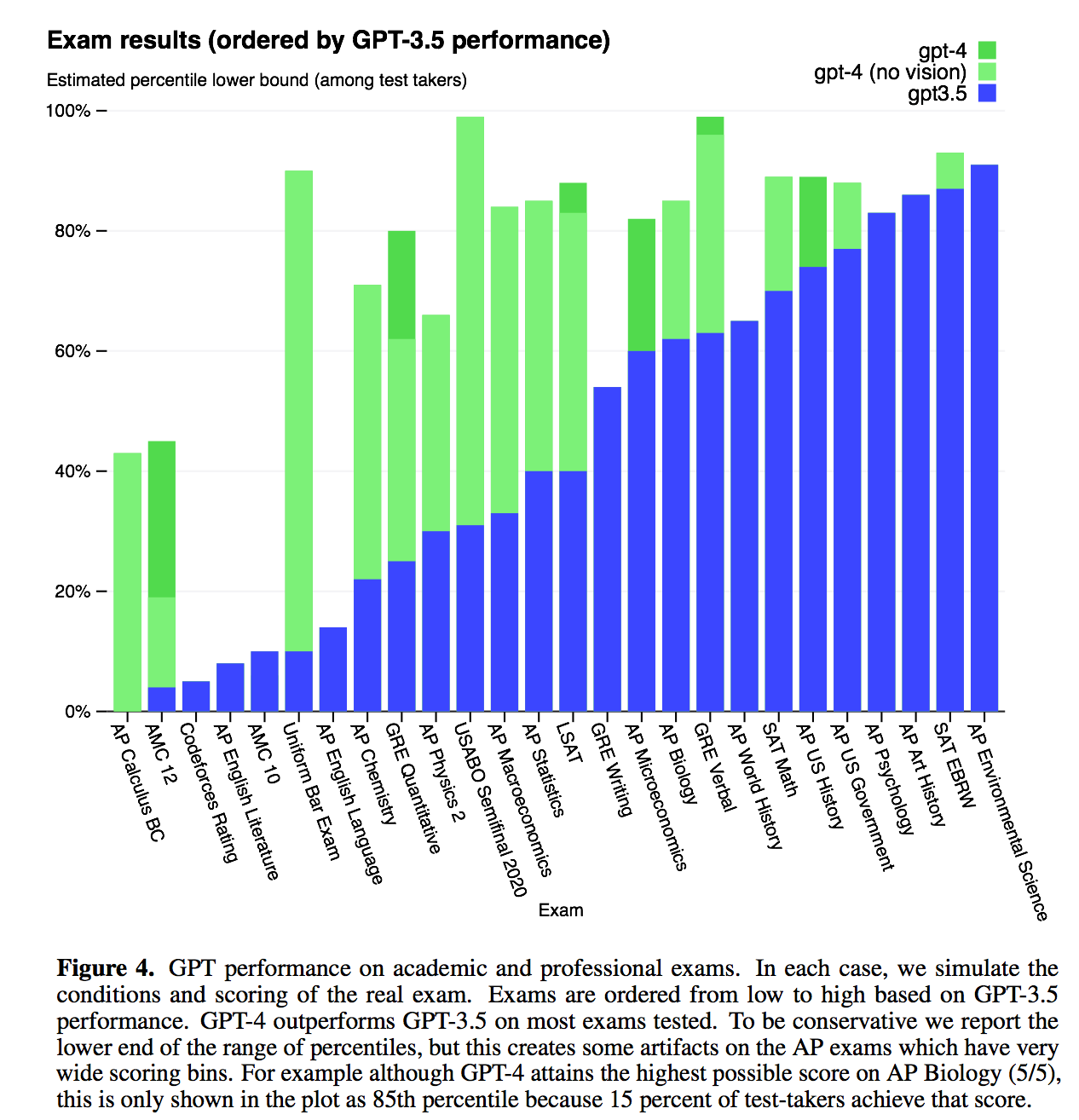
Related Documents
Related Videos
-
LLaVa
Explanation
How does LLaVA work
LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and an LLM for general- purpose visual and language understanding. To facilitate future research on visual instruction following, we construct two evaluation benchmarks with diverse and challenging application-oriented tasks. Our experiments show that LLaVA demon- strates impressive multimodal chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions.
LLaVA is trained in several tasks, including:
- GPT-assisted Visual Instruction Data Generation
- Visual Instruction Tuning
LLaVA multi modal tasks:
- Multimodal Chatbot: Chatbot is trained by fine-tuning on the 158K language-image instruction-following data in Section 3. Among the three types of responses, conversation is multi-turn while the other two are single-turn
- Science QA: The model is finetuned on ScienceQA benchmark, which is the first large-scale multimodal science question dataset that annotates the answers with detailed lectures and explanations.
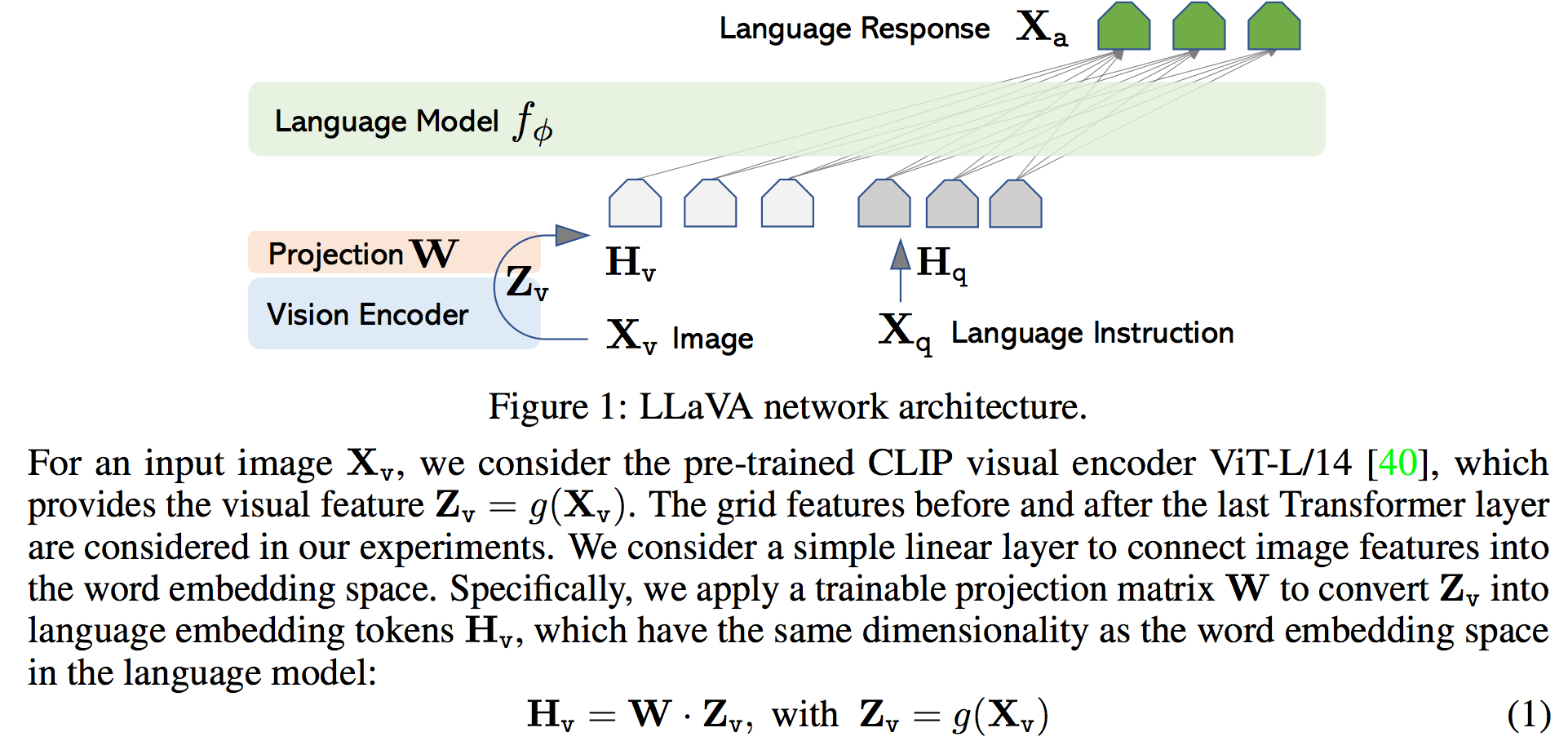
Related Documents
Related Videos
-
KOSMOS-2
Explanation
How does KOSMOS-2 work
KOSMOS-2, a Multimodal Large Language Model (MLLM), enabling new capabilities of perceiving object descriptions (e.g., bounding boxes) and grounding text to the visual world. Specifically, we represent refer expressions as links in Markdown, i.e., “[text span](bounding boxes)”, where object descriptions are sequences of location tokens. Together with multimodal corpora, we construct large-scale data of grounded image-text pairs (called GRIT) to train the model. In addition to the existing capabilities of MLLMs (e.g., perceiving general modalities, following instructions, and performing in-context learning), KOSMOS-2 integrates the grounding capability into downstream applications. We evaluate KOSMOS-2 on a wide range of tasks, including (i) multimodal grounding, such as referring expression comprehension, and phrase grounding, (ii) multimodal referring, such as referring expression generation, (iii) perception-language tasks, and (iv) language understanding and generation.
KOSMOS-2 is trained in several tasks, including:
- Step-1: Generating noun-chunk-bounding-box pairs
- Step-2: Producing referring-expression-bounding-box pairs
- Grounded Input Representations
- Grounded Multimodal Large Language Models
- Instruction Tuning


Related Documents
Related Videos
-
PaLM-E
Explanation
How does PaLM-E work
We propose embodied language models to directly incorporate real-world continuous sensor modalities into language models and thereby establish the link between words and percepts. Input to our embodied language model are multi-modal sentences that interleave visual, continuous state estimation, and textual input encodings. We train these encodings end-to-end, in conjunction with a pre-trained large language model, for multiple embodied tasks including sequential robotic manipulation planning, visual question answering, and captioning. Our evaluations show that PaLM-E, a single large embodied multimodal model, can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains. Our largest model, PaLM-E-562B with 562B parameters, in addition to being trained on robotics tasks, is a visual-language generalist with state-of-the-art performance on OK-VQA, and retains generalist language capabilities with increasing scale.


Related Documents
Related Videos
-
FLAMINGO
Explanation
How does FLAMINGO work
Flamingo is a family of Visual Language Models (VLM) with this ability. We propose key architectural innovations to: (i) bridge powerful pretrained vision-only and language-only models, (ii) handle sequences of arbitrarily inter- leaved visual and textual data, and (iii) seamlessly ingest images or videos as inputs. Thanks to their flexibility, Flamingo models can be trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images, which is key to endow them with in-context few-shot learning capabilities.
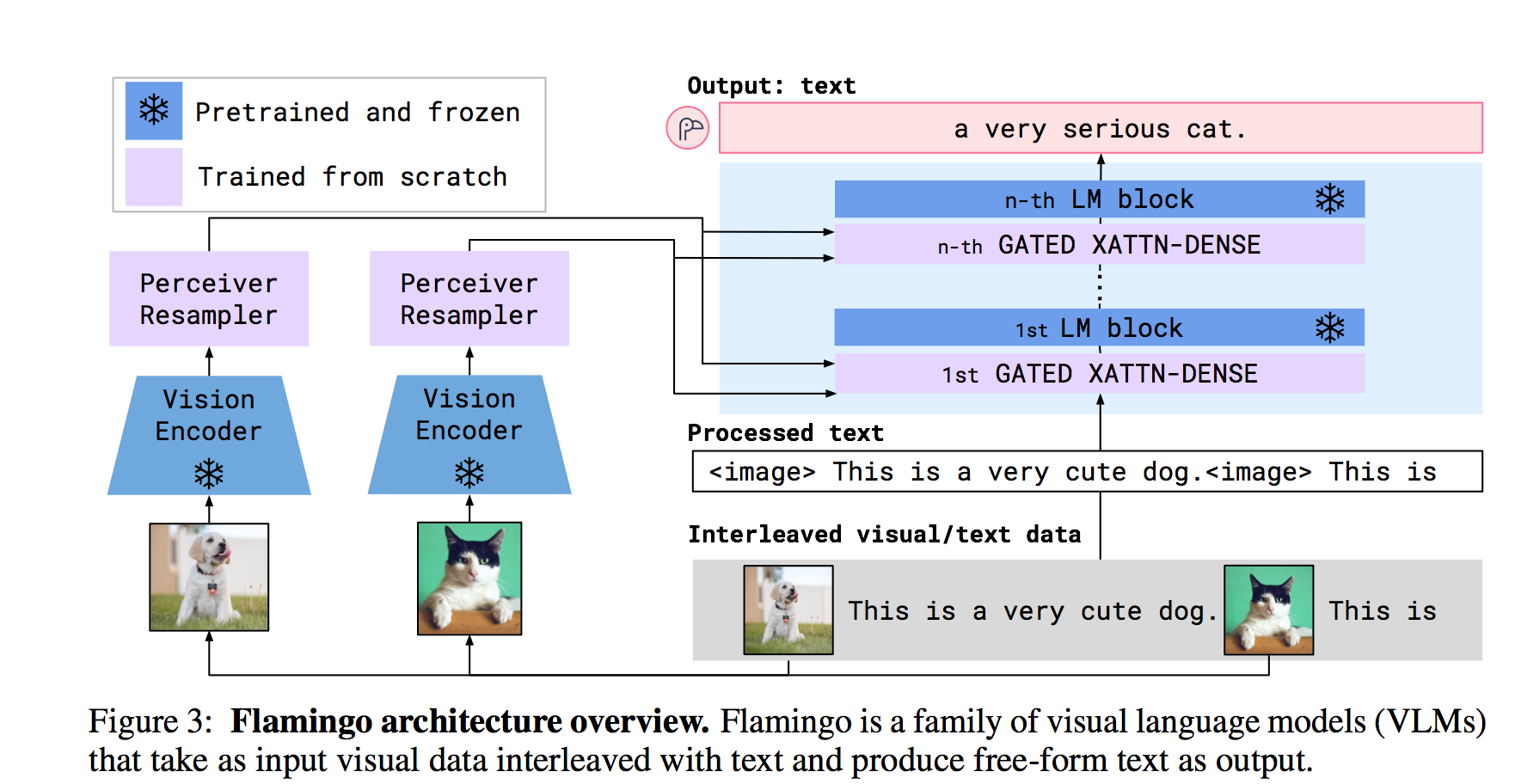
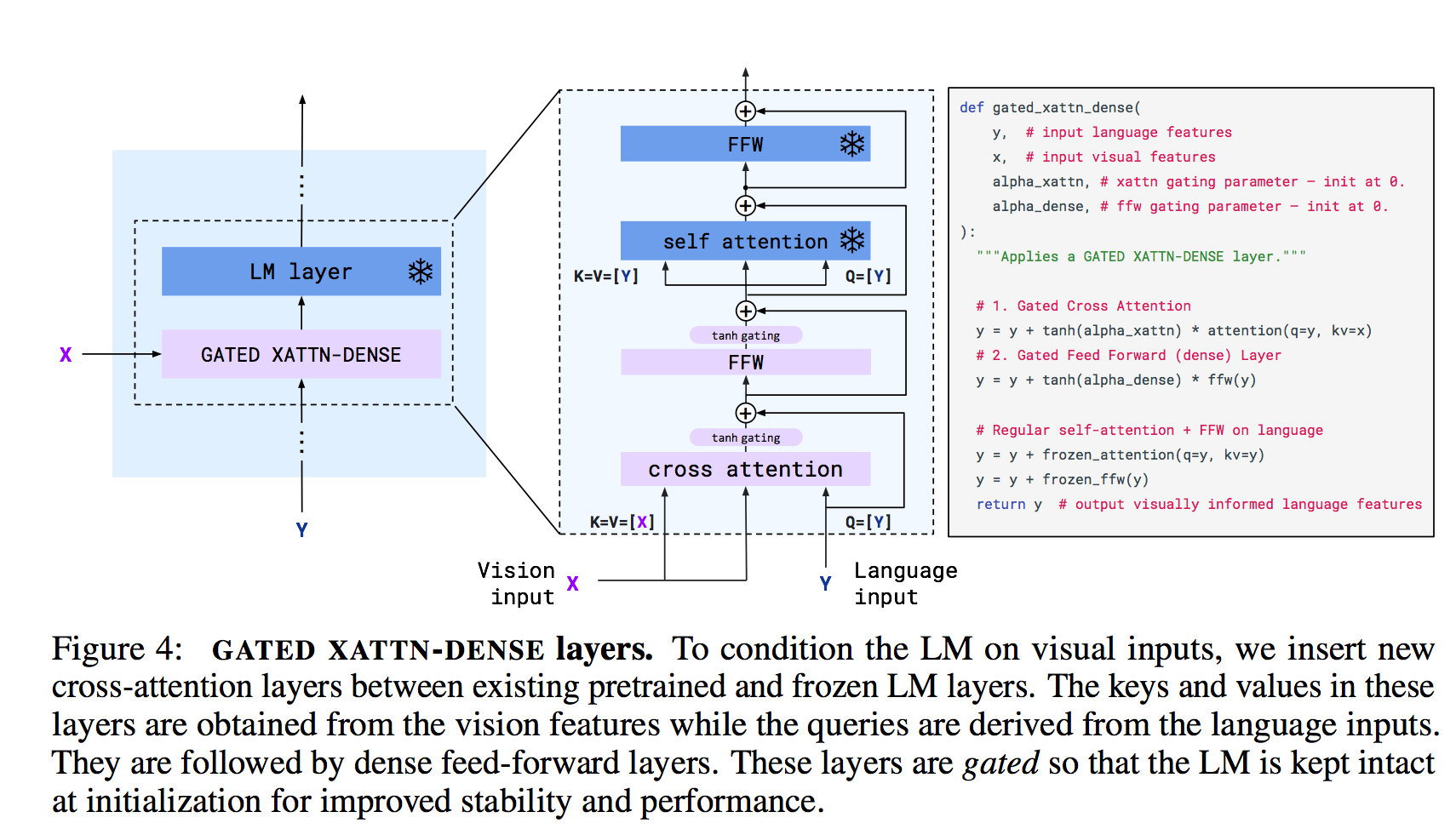
Related Documents
Related Videos
-
Text-Conditional Image Generation with CLIP (unCLIP)
Explanation
How does unCLIP work
To leverage these representations for image generation, we propose a two-stage model: a prior that generates a CLIP image embedding given a text caption, and a decoder that generates an image conditioned on the image embedding. We show that explicitly generating image representations improves image diversity with minimal loss in photorealism and caption similarity. Our decoders conditioned on image representations can also produce variations of an image that preserve both its semantics and style, while varying the non-essential details absent from the image representation. Moreover, the joint embedding space of CLIP enables language-guided image manipulations in a zero-shot fashion. We use diffusion models for the decoder and experiment with both autoregressive and diffusion models for the prior, finding that the latter are computationally more efficient and produce higher-quality samples.
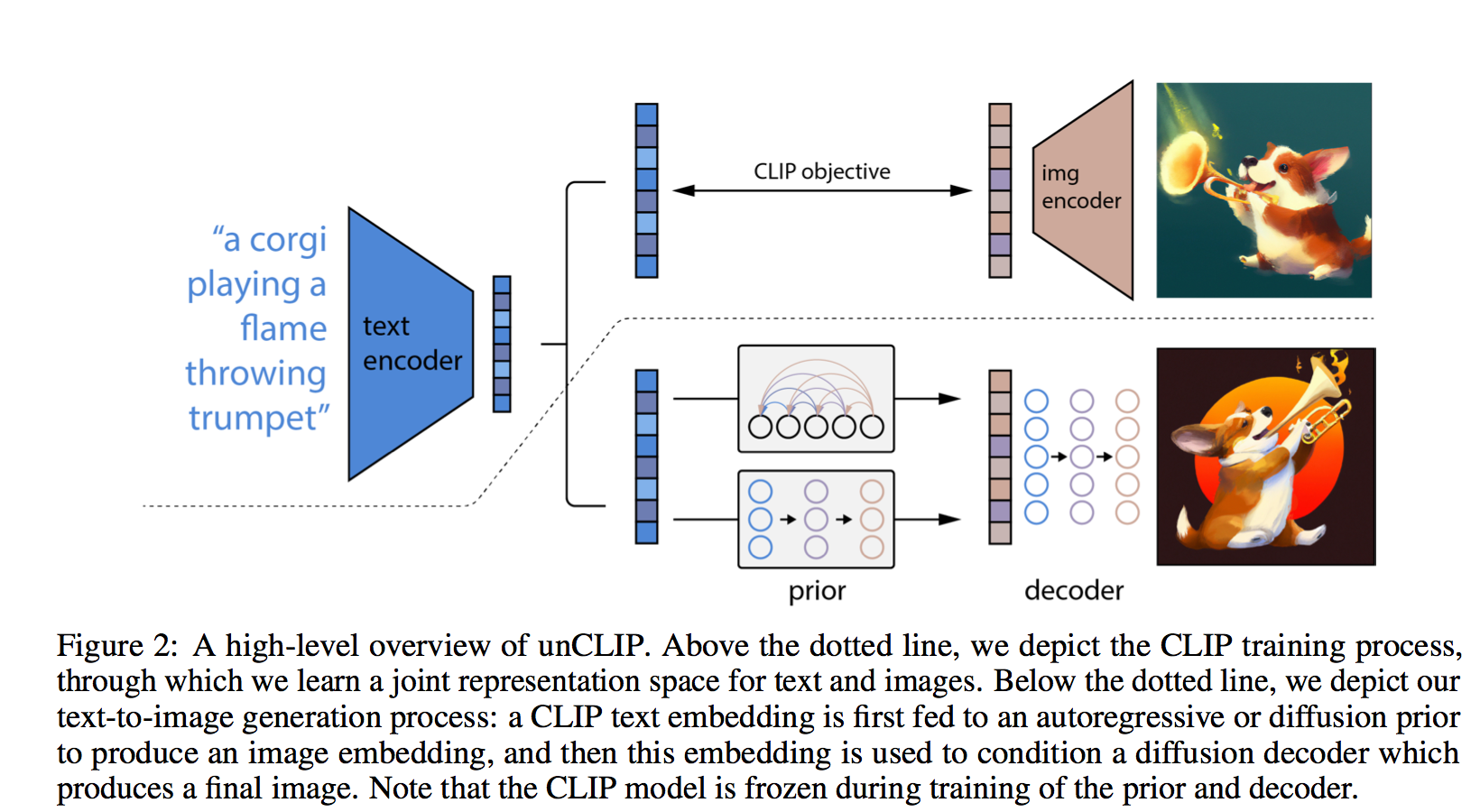
Related Documents
Related Videos
-
BEiT-3
Explanation
How does BEiT-3 work
BEIT-3 is a general-purpose multimodal foundation model which achieves state-of-the-art transfer performance on both vision and vision- language tasks. Specifically, we advance the big convergence from three aspects: backbone architecture, pretraining task, and model scaling up. We introduce Multi- way Transformers for general-purpose modeling, where the modular architecture enables both deep fusion and modality-specific encoding. Based on the shared backbone, we perform masked “language” modeling on images (Imglish), texts (English), and image-text pairs (“parallel sentences”) in a unified manner. Exper- imental results show that BEIT-3 obtains state-of-the-art performance on object detection (COCO), semantic segmentation (ADE20K), image classification (ImageNet), visual reasoning (NLVR2), visual question answering (VQAv2), image captioning (COCO), and cross-modal retrieval (Flickr30K, COCO).
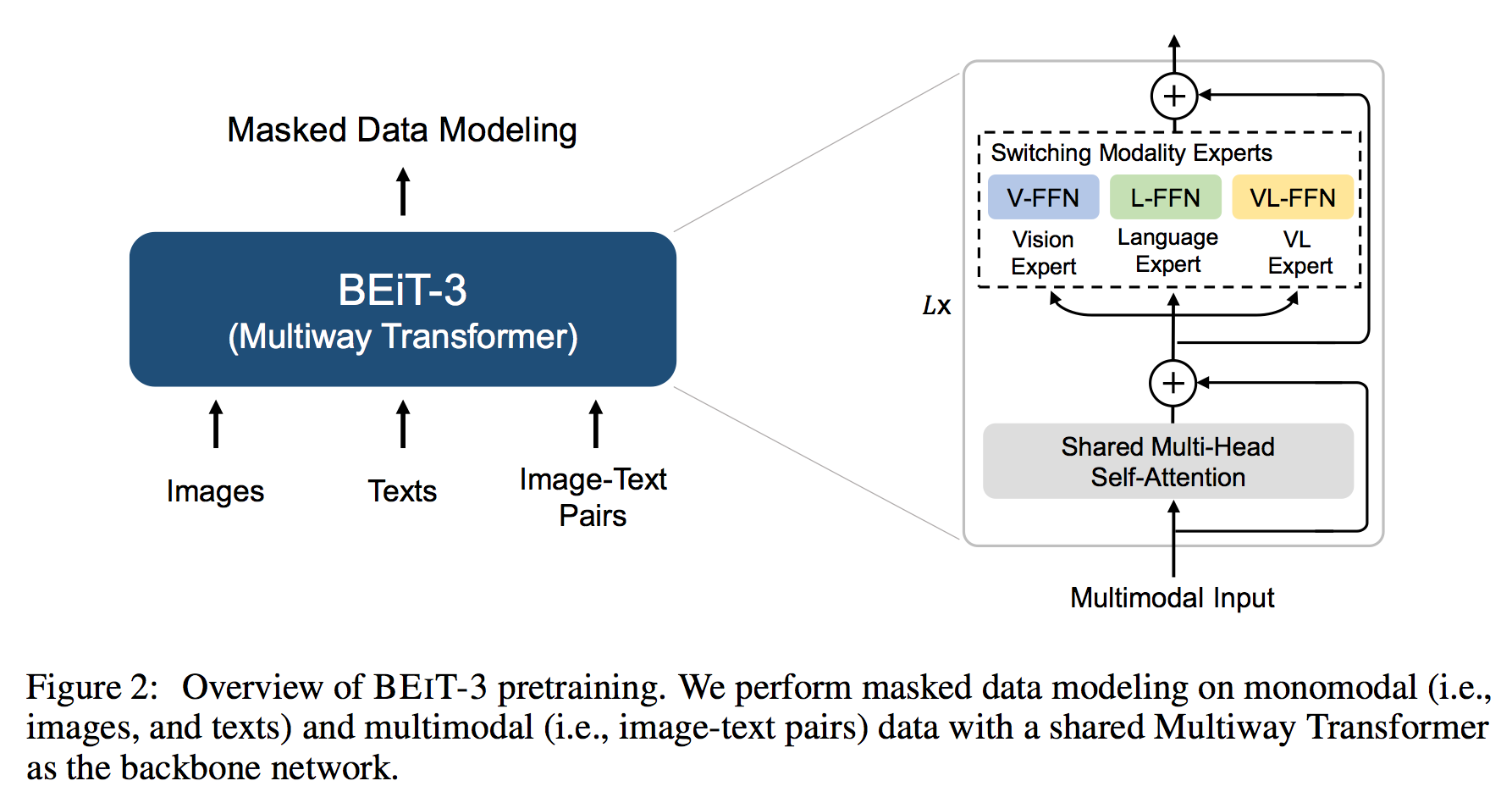
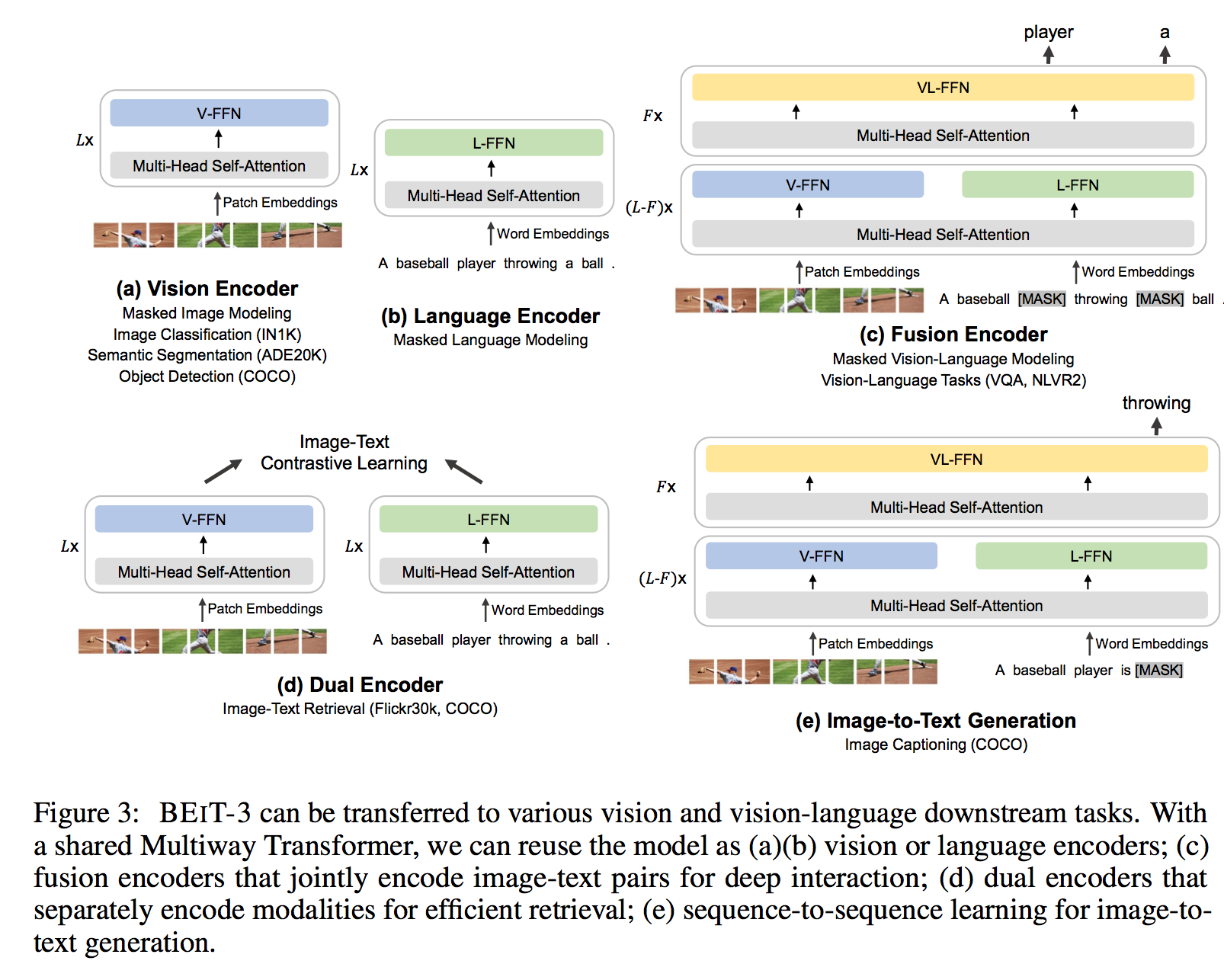
Related Documents
Related Videos
-
CLIP
Explanation
How does CLIP work
Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes with which im- age is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study the performance of this approach by benchmark- ing on over 30 different existing computer vi- sion datasets, spanning tasks such as OCR, ac- tion recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset spe- cific training.
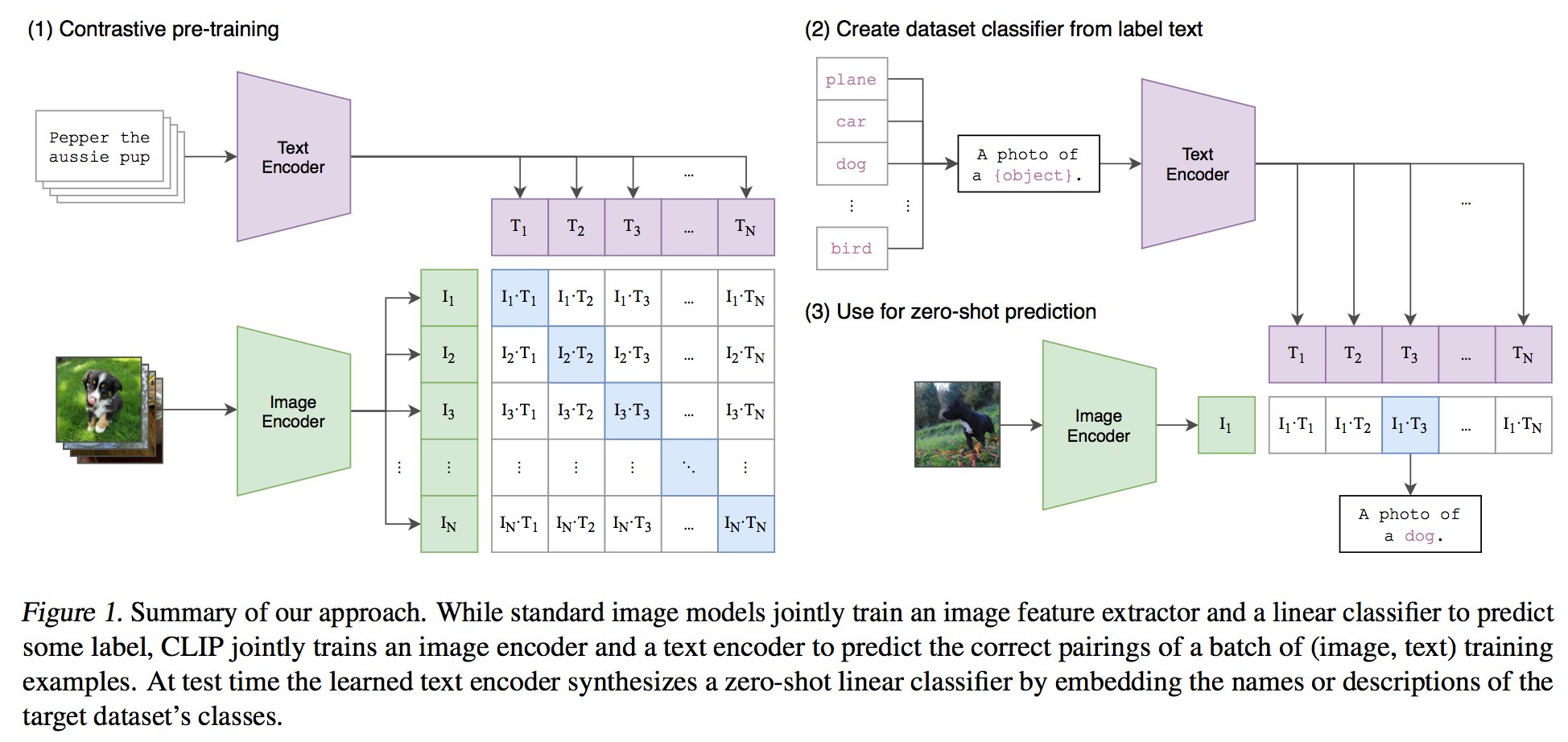
Related Documents
- Learning Transferable Visual Models From Natural Language Supervision
- https://github.com/openai/CLIP
Related Videos