 1
1Introduction to GPT (Generative Pre-trained Transformer) Models, GPT4,ChatGPT Equations and Latex Code
Navigation
In this blog, we will summarize the latex code of most fundamental equations of GPT (Generative Pre-trained Transformer) Models. This blog will cover many popular GPT models, including GPT1, GPT2, GPT3, GPT4, InstructGPT, ChatGPT, etc.
- 1. GPT (Generative Pre-trained Transformer)
- 1.0 GPT1&GPT2 (Language models are unsupervised multitask learners)
- 1.1 GPT3 (Language Models are Few-Shot Learners)
- 1.2 InstructGPT
- 1.3 ChatGPT
- 1.4 GPT4
1. GPT (Generative Pre-trained Transformer)
-
1.0 GPT1/GPT2 (Language models are unsupervised multitask learners)
Abstract
Natural language processing tasks, such as question answering, machine translation, reading comprehension, and summarization, are typically approached with supervised learning on taskspecific datasets. We demonstrate that language models begin to learn these tasks without any explicit supervision when trained on a new dataset of millions of webpages called WebText. When conditioned on a document plus questions, the answers generated by the language model reach 55 F1 on the CoQA dataset - matching or exceeding the performance of 3 out of 4 baseline systems without using the 127,000+ training examples. The capacity of the language model is essential to the success of zero-shot task transfer and increasing it improves performance in a log-linear fashion across tasks. Our largest model, GPT-2, is a 1.5B parameter Transformer that achieves state of the art results on 7 out of 8 tested language modeling datasets in a zero-shot setting but still underfits WebText. Samples from the model reflect these improvements and contain coherent paragraphs of text. These findings suggest a promising path towards building language processing systems which learn to perform tasks from their naturally occurring demonstrations.
Language Modelling
Latex Code
p(x)=\prod^{n}_{i=1} p(s_{n}|s_{1},...,s_{n-1})Explanation
: Language modeling is usually framed as unsupervised distribution estimation from a set of examples of
: Variable length sequences of symbols
: Factorize the joint probabilities over symbols p(x) as the product of conditional probabilities
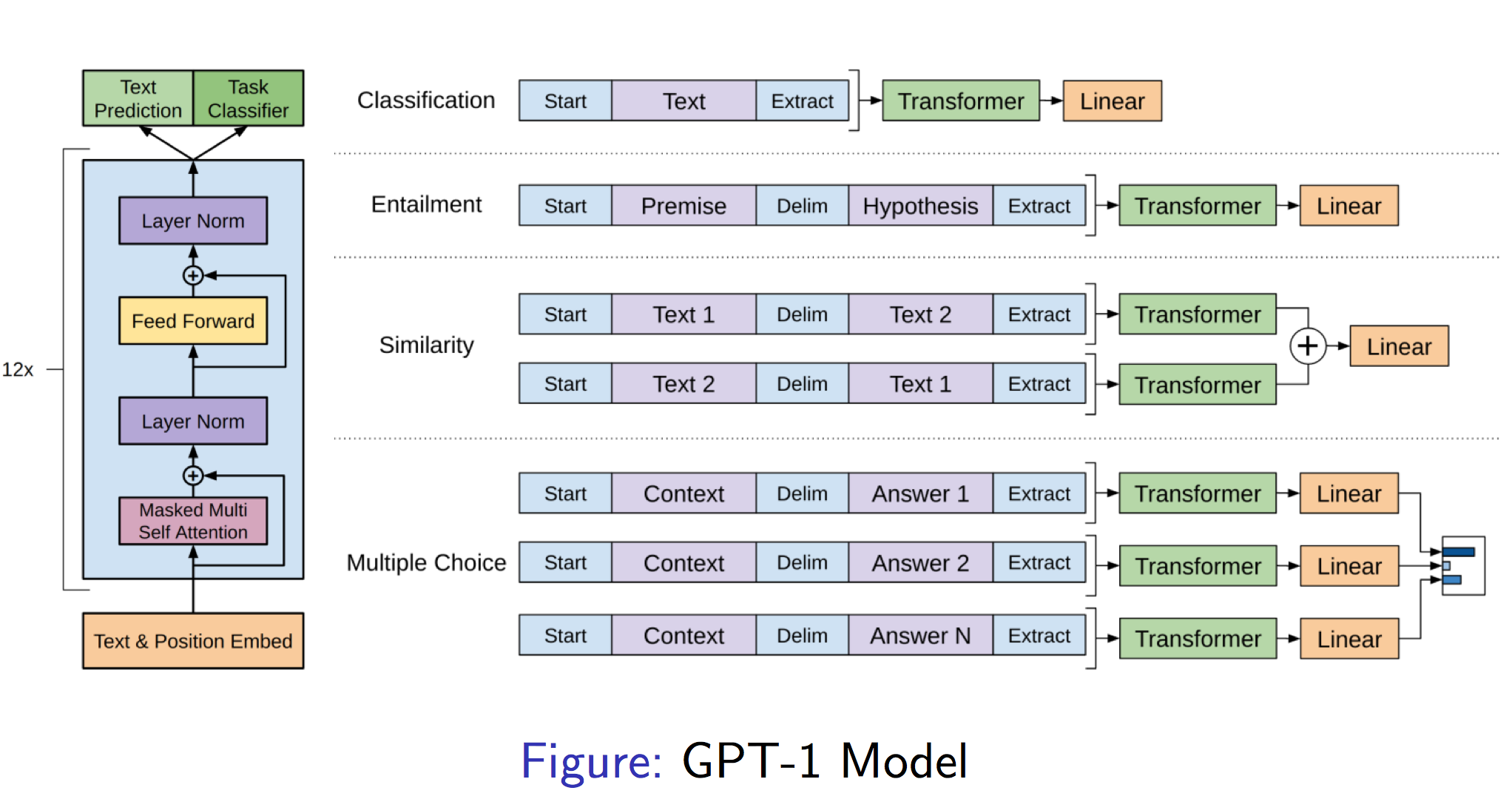
You can check more detailed information of GPT2 in this Language Models are Unsupervised Multitask Learners and tutorial for more details.
-
1.1 GPT3 (Language Models are Few-Shot Learners)
Abstract
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples. By contrast, humans can generally perform a new language task from only a few examples or from simple instructions - something which current NLP systems still largely struggle to do. Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches. Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic. At the same time, we also identify some datasets where GPT-3's few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora. Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans. We discuss broader societal impacts of this finding and of GPT-3 in general.
Explanation
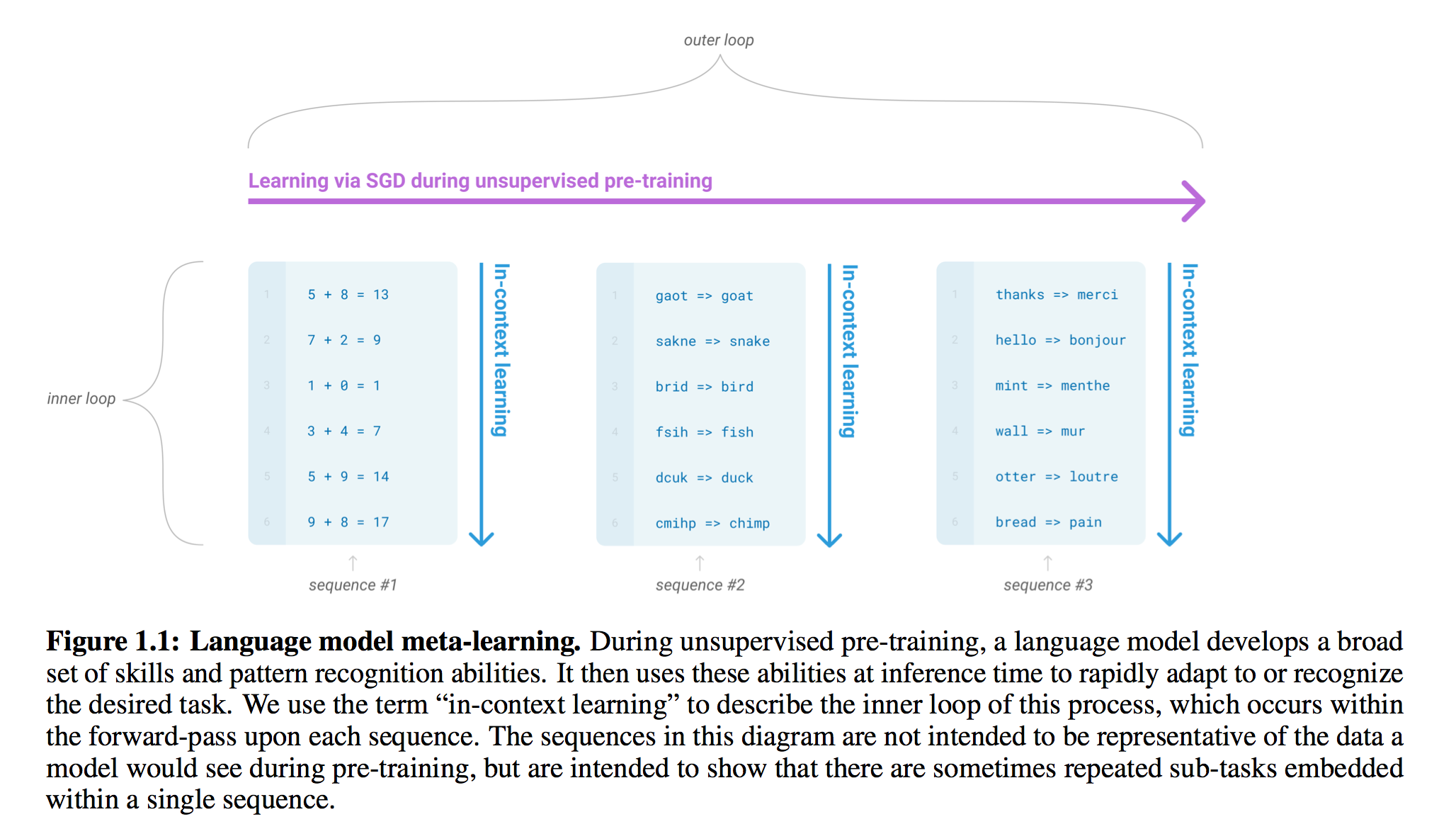

You can check more detailed information of GPT3 in this Language Models are Few-Shot Learners for more details.
-
1.2 InstructGPT
Abstract
Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users. In this paper, we show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback. Starting with a set of labeler-written prompts and prompts submitted through the OpenAI API, we collect a dataset of labeler demonstrations of the desired model behavior, which we use to fine-tune GPT-3 using supervised learning. We then collect a dataset of rankings of model outputs, which we use to further fine-tune this supervised model using reinforcement learning from human feedback. We call the resulting models InstructGPT. In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters. Moreover, InstructGPT models show improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets. Even though InstructGPT still makes simple mistakes, our results show that fine-tuning with human feedback is a promising direction for aligning language models with human intent.
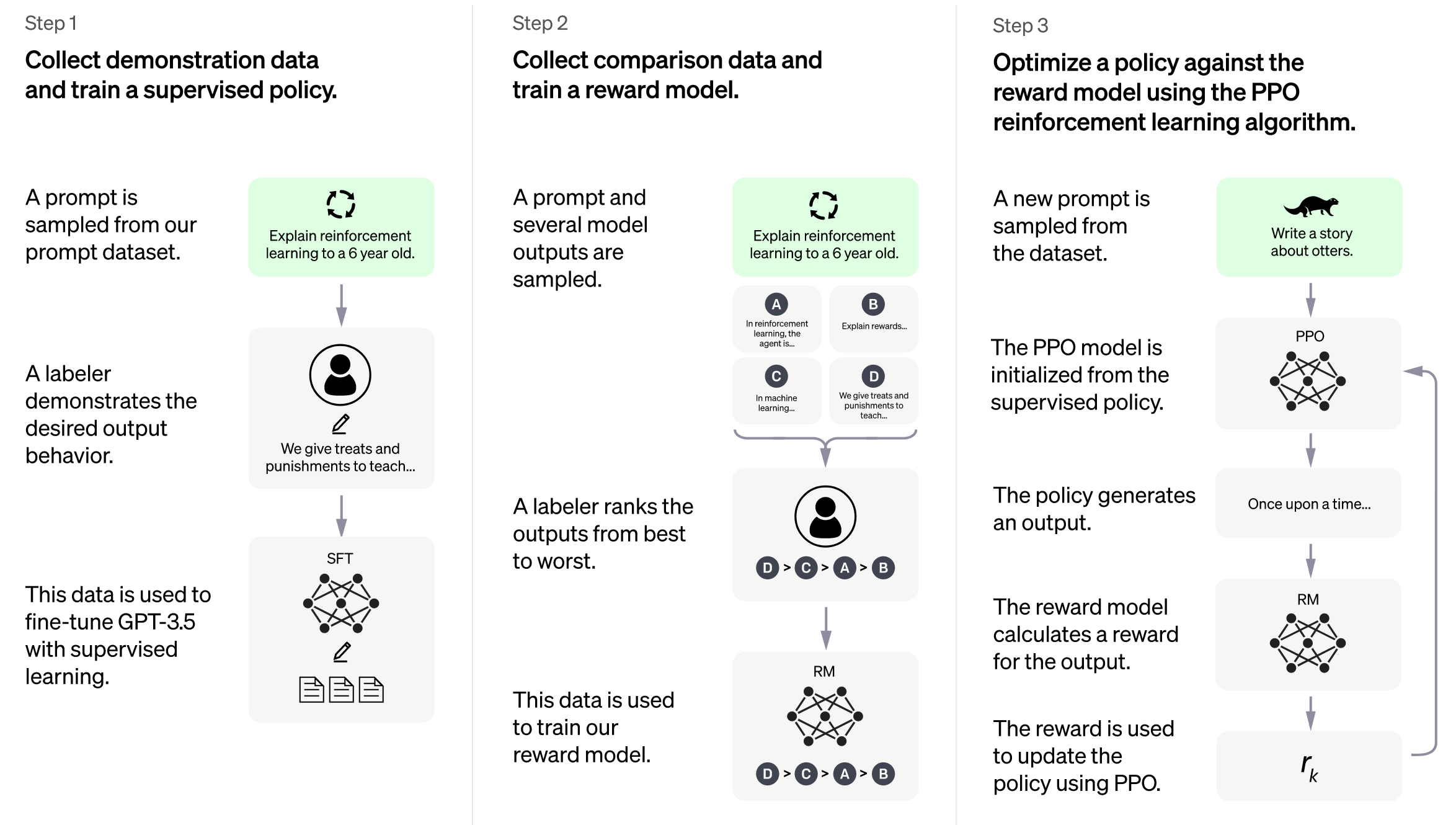
High-level methodology
- Step 1: Collect demonstration data, and train a supervised policy.
- Step 2: Collect comparison data, and train a reward model.
- Step 3: Optimize a policy against the reward model using PPO.
Our labelers provide demon- strations of the desired behavior on the input prompt distribution (see Section 3.2 for details on this distribution). We then fine-tune a pretrained GPT-3 model on this data using supervised learning.
We collect a dataset of comparisons between model outputs, where labelers indicate which output they prefer for a given input. We then train a reward model to predict the human-preferred output.
We use the output of the RM as a scalar reward. We fine-tune the supervised policy to optimize this reward using the PPO algorithm (Schulman et al., 2017).
Models
- 1. Supervised fine-tuning (SFT)
- 2. Reward modeling (RM)
- 3. Reinforcement learning (RL) PPO
You can check more detailed information of InstructGPT in this paper Training language models to follow instructions with human feedback for more details.
Reward Model(RM) Equation
Latex Code
\text{loss}(\theta)=-\frac{1}{A^{2}_{K}}E_{(x,y_{w},y_{l}) \sim D}[\log (\sigma(r_{\theta} (x, y_{w}) - r_{\theta} (x, y_{l})))]Explanation
: scalar output of the reward model for prompt x and completion y with parameters \theta
: is the preferred completion out of the pair of y_{w} and y_{l}
: is the dataset of human comparisons.
Reinforcement learning and PPO
Latex Code
\text{obejctive}(\phi)=E_{(x,y)}\sim D_{\pi^{\text{RL}}_{\phi}} [r_{\theta}(x,y) - \beta \log (\pi^{\text{RL}}_{\phi}(y|x)/\pi^{\text{SFT}}(y|x))] + \gamma E_{x \sim D_{pretrain}}[\log(\pi^{\text{RL}}_{\phi}(x))]Explanation
: is the learned RL policy
: is the supervised trained model
: is the pretraining distribution.
: The KL reward coefficient
: Pretraining loss coefficient
-
1.3 ChatGPT
Abstract
We've trained a model called ChatGPT which interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests.
Proximal Policy Optimization(PPO)
With supervised learning, we can easily implement the cost function, run gradient descent on it, and be very confident that weâ??ll get excellent results with relatively little hyperparameter tuning. The route to success in reinforcement learning isnâ??t as obviousâ??the algorithms have many moving parts that are hard to debug, and they require substantial effort in tuning in order to get good results. PPO strikes a balance between ease of implementation, sample complexity, and ease of tuning, trying to compute an update at each step that minimizes the cost function while ensuring the deviation from the previous policy is relatively small. https://openai.com/research/openai-baselines-ppo
Latex Code
L^{CLIP}(\theta)=E_{t}[\min(r_{t}(\theta))A_{t}, \text{clip}(r_{t}(\theta), 1-\epsilon,1+\epsilon)A_{t}]Explanation
: is the policy parameter
: denotes the empirical expectation over timesteps
: is the ratio of the probability under the new and old policies, respectively
: is the estimated advantage at time t
: is a hyperparameter, usually 0.1 or 0.2
-
1.4 GPT4 (Multi-Module)
Abstract
We report the development of GPT-4, a large-scale, multimodal model which can accept image and text inputs and produce text outputs. While less capable than humans in many real-world scenarios, GPT-4 exhibits human-level performance on various professional and academic benchmarks, including passing a simulated bar exam with a score around the top 10% of test takers. GPT-4 is a Transformer-based model pre-trained to predict the next token in a document. The post-training alignment process results in improved performance on measures of factuality and adherence to desired behavior. A core component of this project was developing infrastructure and optimization methods that behave predictably across a wide range of scales. This allowed us to accurately predict some aspects of GPT-4's performance based on models trained with no more than 1/1,000th the compute of GPT-4.
Explanation
- You can check more detailed information of GPT3 in this GPT-4 Technical Report for more details.
- GPT4 Website